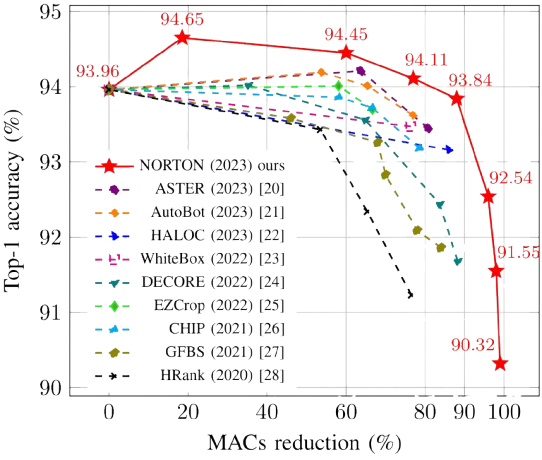
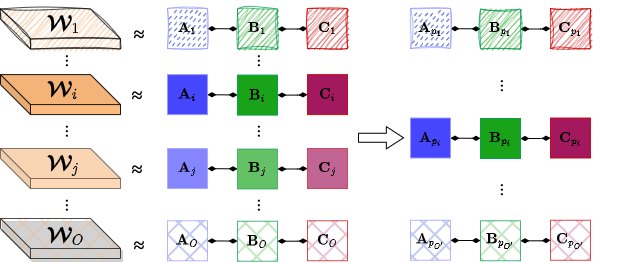
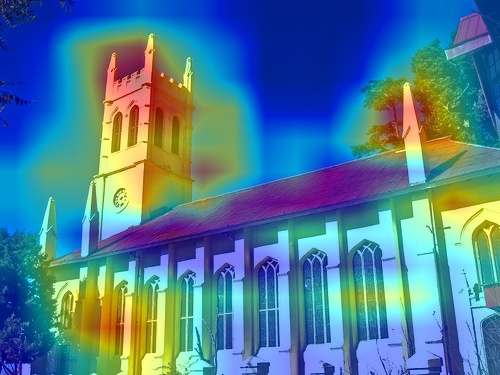
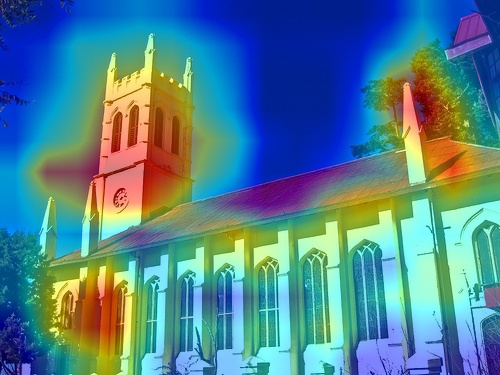
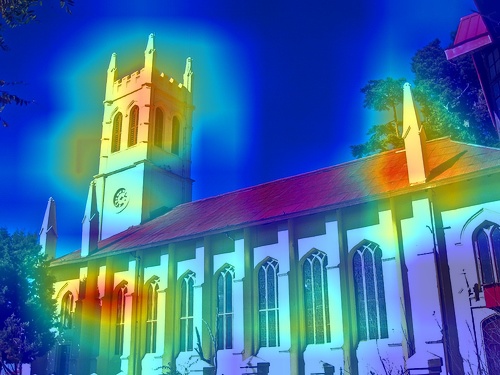
💪 Motivation
Tensor decomposition has emerged as an effective tool for compressing convolutional neural networks by exploiting the low-rank structure of weight tensors. Existing approaches typically focus on which decomposition to use and how to select the rank, while implicitly assuming that the convolutional weights should be decomposed at the level of the entire layer.
However, a convolutional layer weight is inherently a 4-order tensor, and the way this tensor is handled prior to decomposition has a major impact on both compression efficiency and approximation quality. Prior works either decompose the whole layer directly, or reshape the tensor into a lower-order form before applying decomposition. These strategies operate at a coarse granularity and may either limit flexibility or compromise the original multidimensional structure.
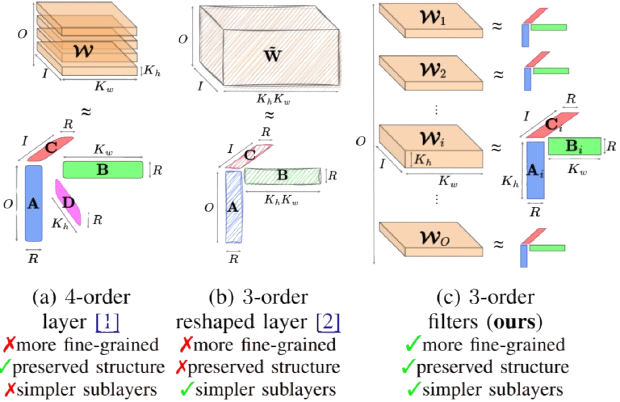
In contrast, we observe that convolution operates on a filter-by-filter basis: each output feature map is produced independently by convolving the input with a single filter. This motivates a more fine-grained perspective, where the 4-order weight tensor is naturally interpreted as a collection of 3-order filter tensors.
Building on this observation, NORTON adopts a filters decomposition strategy, in which each filter is decomposed individually. This preserves the full multidimensional structure, avoids unnecessary tensor reshaping, and yields a narrower and more stable range of ranks. Moreover, filters decomposition replaces a convolutional layer with fewer sublayers than layer-wise decomposition, reducing architectural complexity and facilitating subsequent compression steps.